a paradigm shift in data architecture
Technological advances, increasing business requirements and regulations (such as GDPR and CCPA) are important drivers in data architecture evolution.
Today, various architecture models and diagrams are implemented:
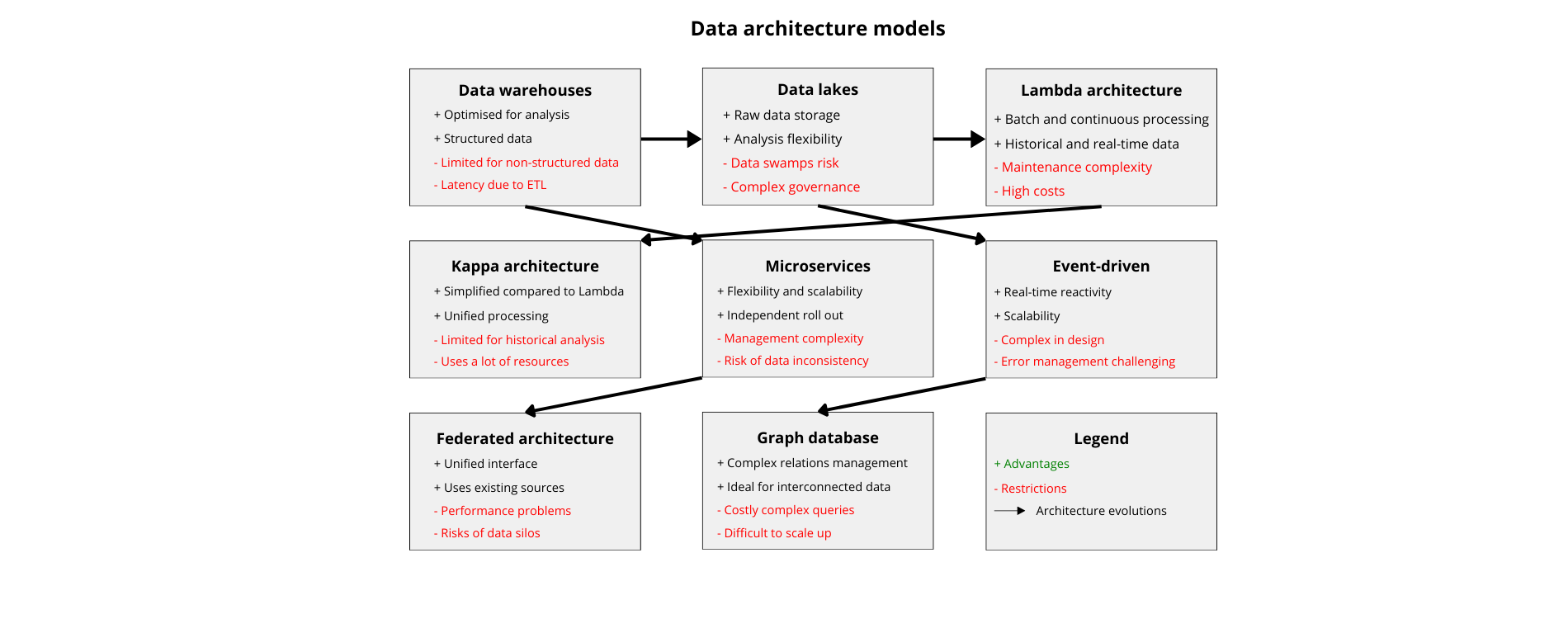
Traditional data warehouses
These are centralised repositories for structured data, optimised for analytical queries and reports. Data warehouses typically follow a write schema approach, in which data is structured and transformed before being uploaded to the warehouse. The most popular traditional data warehouses are Oracle Exadata, IBM Netezza, and Teradata.
Restrictions:
- Massive volumes of data generated by applications
- Difficulties in adapting to semi–structured or unstructured data formats
- ETL processes can introduce latency, making real-time information complex to provide
Data Lakes
These are centralised repositories that store raw, unstructured or semi-structured data at scale. Unlike data warehouses, data lakes allow organisations to store data in its original format and perform various types of analytics, including exploratory analysis, machine learning, and ad hoc queries. Popular technologies for creating data lakes include Apache Hadoop, Apache Spark, and Amazon S3.
Restrictions:
- Without proper governance, data lakes can turn into data swamps, making it difficult to find and trust relevant data.
- Managing and organising a large volume of raw data in a data lake requires detailed planning and metadata management.
- Storing raw data without pre-processing can lead to data quality issues, prompting additional effort for cleanup and transformation.
Lambda architecture
A hybrid approach that combines batch and continuous processing to manage both historical and real-time data. It usually consists of three layers:
- A batch layer to store and process historical data,
- A speed layer to manage real-time data,
- A serving layer to query and serve results.
Apache Kafka, Apache Hadoop, and Apache Spark are commonly used in Lambda architectures.
Restrictions:
- Implementing and maintaining separate batch and speed layers can introduce complexity to the architecture.
- Ensuring consistency between the batch and speed layers can be challenging and may require extra synching mechanisms.
- Managing multiple layers and technologies increases operational overhead and maintenance costs.
Kappa architecture
A simplified version of the Lambda architecture that exclusively uses stream processing for real-time and batch data. It eliminates the need for separate processing layers, resulting in a more streamlined and scalable architecture.
Restrictions:
- Since Kappa architecture is mainly based on stream processing, the historical data analysis can be limited compared to Lambda architecture.
- Processing all data in real time can be resource intensive and may require scalable infrastructure to handle maximum workloads.
Microservices architecture
The breakdown of applications into small independent services that can be independently developed, rolled out and scaled. Each microservice usually has its own database, and data is exchanged between services via APIs. Microservices architecture provides flexibility, scalability, and resilience, but it also introduces challenges related to data consistency and management.
Restrictions:
- Maintaining data consistency across multiple microservices can be challenging, especially in distributed systems.
- Managing a large number of microservices introduces operational complexity, including rolling out, monitoring, and debugging.
- Data duplication between several microservices involves risks of inconsistency and synching issues.
Event-driven architecture:
Event-driven architecture is based on production, detection, consumption, and reaction to events. Events are generated from various sources and can trigger actions in real time. Event-driven architectures are ideal for scenarios that require responsiveness and scalability.
Restrictions:
- Designing event-oriented systems is complex and requires thorough consideration of the source of events, their distribution, and final consistency.
- Real-time event management and processing introduces complexities in error management and
- Scaling event-driven architectures to handle large volumes of events requires solid infrastructure and monitoring capabilities.
Federated architecture
Data remains decentralised across multiple systems or locations, but is accessible through a unified interface. This approach allows organisations to leverage existing data sources without centralising data storage.
Restrictions:
- Accessing data from multiple sources can introduce performance and latency issues, especially for complex queries.
- Federated architectures can continue with data silos if not properly designed and implemented, limiting data sharing and integration.
- Federated architectures can introduce security challenges, particularly with regard to data access controls and authentication mechanisms.
Graph database architecture
Data is represented as nodes, edges, and properties, making it well suited for managing complex relationships and interconnected data. Graph database architectures are commonly used in applications such as social media, recommendation engines, and fraud detection systems.
Restrictions:
- Complex queries running through large graphs can be costly in terms of calculation and may require optimisation techniques.
- Designing an efficient graph data model requires data relationships and structure to be considered in detail.
- Scaling graph databases to handle large graphics with millions of nodes and edges can be challenging.
As can be seen through this macro analysis, traditional models face obstacles to development due to the constant increase in data volume and complexity. In addition, centralised architectures often create data silos and choke points, hampering accessibility and collaboration in the organisation. In addition, enforcing consistent data governance policies across the organisation can be a challenge for these centralised architectures. In addition, these models are vulnerable to single points of failure and can struggle to maintain data availability in the event of disruptions. Faced with these challenges, what kind of architecture can efficiently overcome these limitations?
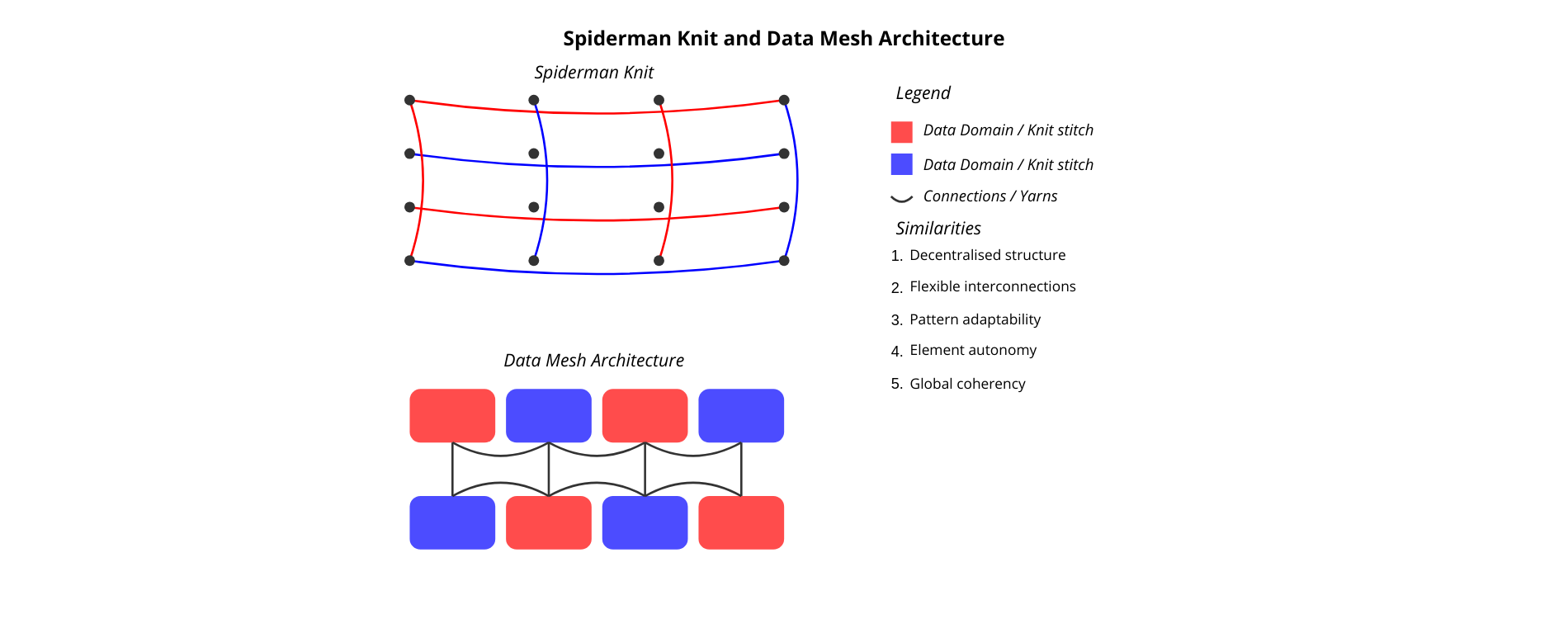
Spiderman Knit and Data Mesh architecture
“Spiderman Knit” alludes to a knitting style or technique used to design a fabric reminiscent of spider webs or Spiderman’s suit. This technique involves using loops or intertwined stitches to create a texture resembling the intricate structure associated with the superhero. Spiderman knit involves working on different parts of the fabric simultaneously to create a pattern, rather than taking a centralised approach. Spiderman knit designs vary in complexity and design, offering great flexibility and adaptability. This description highlights the interconnected, decentralised and adaptable features of the “Spiderman Knit”.
Similarly, let’s consider the distribution of data between specific domains, each being responsible for its own data services and products. Just as the interwoven yarns of a Spiderman knit form a coherent pattern, this architecture relies on interconnected data services and products to meet the organisation’s data needs. By taking a decentralised approach to data ownership and management, domain-specific teams can take charge of their own data and create data products tailored to their needs. This decentralised approach fosters agility, scalability and innovation, as well as the flexibility and creativity needed to design a Spiderman-inspired pattern. This architecture can adapt to various data sources, formats, and use cases, so organisations can tailor their data infrastructure to their specific needs.
This is DATA MESH architecture, based on fundamental principles that promote data domain decentralisation, interoperability and autonomy.
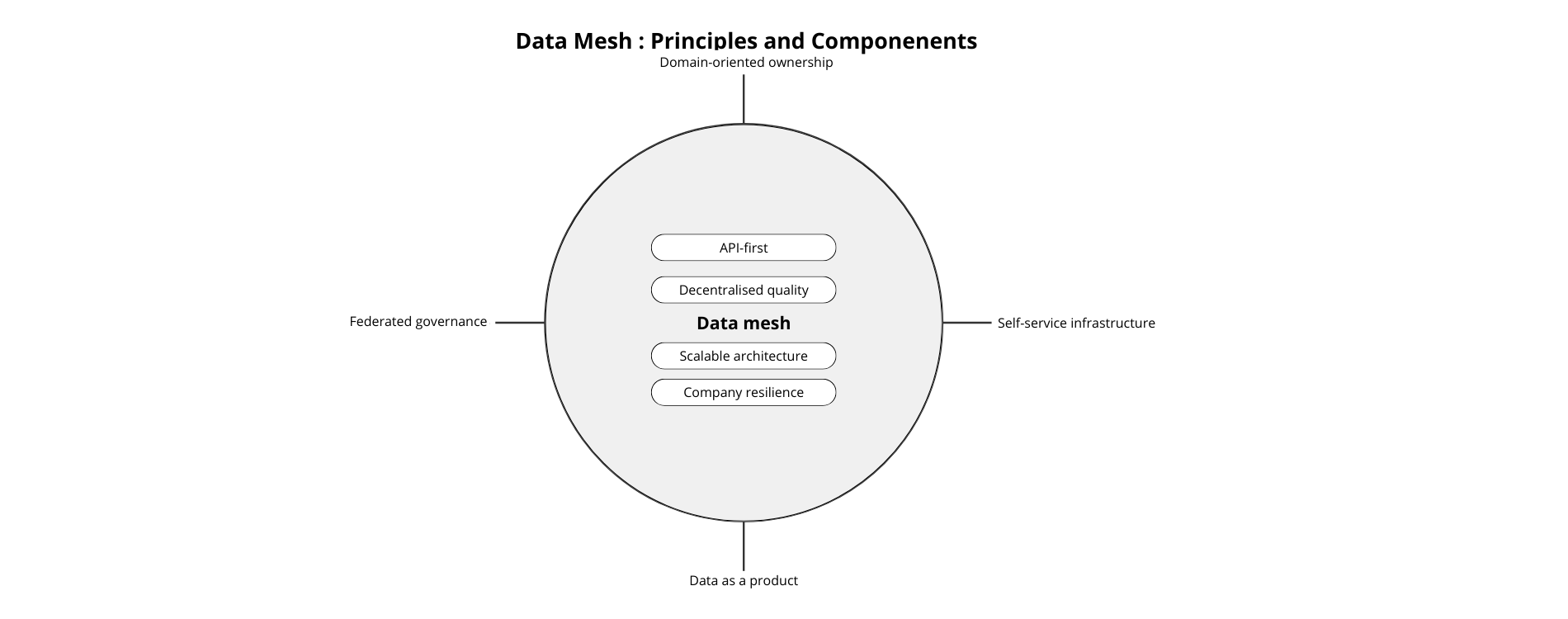
Basic principles
The principles of data mesh are laid to guide its development and roll out. They are designed to address the issues of traditional centralised data architectures and promote a decentralised, domain-based approach to data management.
- Domain-oriented data ownership: Data ownership and governance is decentralised, with domain-specific teams supporting the data they produce and use. Each domain team is responsible for defining and managing its own data services and products.
- Self-service data infrastructure: Domain teams benefit from self-service access to infrastructure and data tools, enabling them to autonomously create, deploy, and operate data products. This approach reduces dependency on centralised data teams and fosters agility and autonomy.
- Data as a product: Data is considered as a product, consumed and improved by the domain teams. This shift in perspective encourages domain teams to focus on creating value through their data services and products, in the same way as for software products.
- Data mesh architecture and platform: The organisation invests in setting up a data mesh architecture and platform that provides the infrastructure, tools, and standards needed to help domain teams manage their data products. This includes features such as data discovery, metadata management, and data governance.
- Federated Data Governance: Data governance is federated, with domain teams responsible for defining and implementing governance policies tailored to their specific needs. This allows domain teams to maintain their autonomy while ensuring compliance with organisational standards and regulations.
- User-centred design and product thinking: Domain teams adopt a product thinking approach and user-centred design principles to develop data products that meet the needs of their users. This involves understanding user needs, iterating based on feedback, and prioritising features that deliver the most value.
- API-first approach: Data products expose APIs that enable other teams in the domain to discover, access, and integrate data in a standardised and interoperable manner. This promotes reusability, interoperability and collaboration across domains.
- Data observability and decentralised quality: Domain teams are responsible for ensuring their data products’ quality, reliability and observability. This involves implementing data quality controls, monitoring data pipelines, and providing visibility of data usage and performance.
- Scalable architecture and continuous improvement: The data mesh architecture is designed to evolve over time in response to evolving business needs and technological advancements. Domain teams are encouraged to experiment, iterate and continuously improve their data infrastructures and products.
By adhering to these fundamental principles, organisations can benefit from a decentralised, data-centric approach to areas of data management, such as increased agility, scalability, and innovation, while overcoming the issues of centralised data architectures such as data silos, complexity, and scalability limitations.
Towards business resilience and data convergence
By adopting the principles of Data Mesh, organisations can strengthen their business resilience by decentralising data ownership, enabling self-service capabilities, establishing federated governance, adopting an API-centric approach, implementing a scalable architecture, and encouraging a data product thinking culture.
This is how to do that:
1. Decentralised data ownership:
By decentralising data ownership, Data Mesh allows each domain team to manage their own data products. This approach reduces dependency on centralised teams and systems, thereby strengthening the organisation’s resilience to disruption. If there is an issue in one domain, the other domains can continue to operate autonomously, thereby limiting impact on the whole business.
2. Self-service data infrastructure
Within the Data Mesh framework, self-service access to data infrastructure and tools is encouraged for domain teams. This approach allows teams to quickly adjust their data products and infrastructures to meet changing business needs, without relying on centralised resources. Self-service capabilities improve agility and enable faster response to disruptions, helping the business maintain operations during challenging times.
3. Federated governance:
With a federated governance approach, each domain team is responsible for defining and implementing governance policies tailored to their specific needs. This ensures compliance with regulations and organisational standards while meeting various business requirements. Federated governance reduces choke points and strengthens the organisation’s ability to adapt to regulatory changes or disruptions.
4. API-First approach:
In the Data Mesh framework, an API-First approach is encouraged for data integration, thereby facilitating data access and exchange between different systems and teams. APIs provide standardised interfaces for data sharing, supporting seamless integration and interoperability between data products. This approach facilitates collaboration and allows the company to quickly adjust its processes and systems in response to disruptions or new requirements.
5. Scalable architecture:
Data Mesh architecture is designed to evolve with changing business needs and technological advancements. Domain teams are encouraged to continuously experiment, iterate and improve their data infrastructures and products. This scalable approach fosters innovation and adaptability, ensuring the organisation remains resilient to evolving challenges and opportunities.
6. Data product thinking:
By treating data as a product, domain teams are encouraged to focus on creating value for their users. This shift in mindset promotes user-centred design, fast iteration, and continuous improvement of data products. By providing valuable data products that meet user needs, the organisation can better withstand disruption and maintain resilience. These principles enable teams to quickly adapt to disruptions, regulatory changes, and evolving business requirements, ensuring the organisation remains resilient and competitive in a fast-changing environment.
Adoption challenges
While data mesh architecture offers many benefits, organisations can be faced with several challenges when adopting it.
1. Cultural change:
Traditional centralised data architectures often involve centralised control and decision-making, while data mesh promotes decentralisation and autonomy between domain teams. Convincing stakeholders and teams to embrace this cultural change can be challenging and may require strong leadership and change management efforts.
2. Skills and expertise:
Adopting data mesh architecture requires domain teams to have the necessary skills and expertise in areas such as data engineering, data governance, and product management. Organisations may need to invest in training and development initiatives to ensure domain teams have what is needed to effectively manage their data products.
3. Technology complexity:
Implementing data mesh architecture involves rolling out and managing a varied set of technologies, including data infrastructure, tools and platforms. Integrating these technologies and ensuring interoperability can be complex and require a significant initial investment in infrastructure and expertise.
4. Data governance and security:
Decentralising data ownership raises challenges related to data governance, security, and compliance. Ensuring consistent governance policies and security controls across domain teams while enabling flexibility and autonomy can be challenging. Organisations need to establish robust governance frameworks and security measures to mitigate the risks associated with decentralised data management.
5. Data quality and consistency:
Maintaining data quality and consistency across domain teams can be challenging, especially when data comes from disparate systems and sources. Ensuring data quality, reliability, and consistency while enabling autonomy and flexibility requires careful planning, monitoring, and collaboration between domain teams.
6. Integration and interoperability:
Ensuring seamless integration and interoperability while enabling autonomy and self-service access requires standardised APIs, data formats and communication protocols. Organisations need to invest in technologies and integration practices to facilitate data exchange and collaboration.
7. Organisational silos:
Domain teams can focus too much on their own products and data priorities, leading to effort duplication and fragmentation. Organisations need to encourage domain teams to work together and communicate to ensure alignment with broader business goals.
8. Change management:
The transition to data mesh architecture involves significant organisational changes and can encounter resistance from stakeholders who are used to traditional centralised approaches. Effective change management, communication and stakeholder engagement are essential for overcoming resistance and ensuring the data mesh architecture is successfully adopted.
Meeting these challenges requires a comprehenisve approach that involves aligning the organisational culture, developing the skills and expertise required, implementing solid governance and security measures, fostering collaboration and communication, and effectively managing change.
Conclusion: data mesh has transformative potential in the redesign of the data architecture
To sum up, data mesh architecture makes domain teams accountable, fosters collaboration, and ensures data evolves in sync with business needs and technological advancements. This is a paradigm shift that encourages agility and scalability in data management. While adopting data mesh architecture can present challenges, the potential benefits in terms of agility, innovation, and resilience make it a profitable investment for organisations looking to fully exploit their data potential.
“Data Mesh is a decentralised socio-technical approach to access and manage analytical data in large-scale environments.” Zhamak Dehghani
Data Mesh Glossary
- Data Mesh: A decentralised architectural approach to large-scale data management.
- Domain-oriented data ownership: Principle where domain-specific teams are accountable for the data they produce and use.
- Self-service data infrastructure: Tools and platforms that enable domain teams to manage their data autonomously.
- Data as a product: A concept that treats data as a product in its own right, with its own lifecycles and values.
- Federated Data Governance: A governance approach where domain teams define their own policies while adhering to organisational standards.
- API-first: An API-based approach for cross-domain data access and integration.
- Decentralised data quality: Accountability of domain teams to ensure the quality of their own data.
- Scalable architecture: Flexible design allowing the data infrastructure to adjust to changing business needs.
- Business resilience: An organisation’s ability to adapt to and survive disruptions.
- Data convergence: Process for integrating and harmonising data from different sources.
- Organisational silos: Isolation of teams or departments that hinder collaboration and information sharing.
- Structured data: Data organised according to a predefined format, typically stored in relational databases. It can be easily searched and analysed (e.g. spreadsheets, SQL databases).
- Semi-structured data: Data that has a certain organisational structure, but which is not as rigid as structured data. It can contain tags or markers to separate elements (e.g. XML, JSON files).
- Unstructured data: Data that has no predefined structure and is not organised in a predetermined way. It is more difficult to analyse and process with traditional methods (e.g. free text, images, videos).
- Batch processing: A data processing method where a large volume of data is collected over a period of time and then processed in one go. It is used for tasks that do not require real-time results.
- Continuous processing: A data processing approach where data is processed as soon as it arrives, enabling near real-time analysis and reactions.
- Stream processing: A continuous data processing method, specially designed to manage real-time data streams. It allows data to be analysed and reacted to as it arrives, without necessarily storing it permanently.