Euler, ChatGPT and loops
What if we looked at our code differently?
Nine months ago, I joined Davidson as a “right tech developer”. I wanted to reconcile how I made a living as a developer with my personal convictions – I’m trying to be environmentally friendly, and my recent assignments in the car sector led to a certain cognitive dissonance.
Davidson was clear about its intentions, but it was up to me to create a well-traced roadmap. Quite quickly, we decided to create a multi-criteria tool to measure energy impact: I went into this with some fears as to the tool’s consumption (of energy, in fact) compared to the potential gains.
But that is not the issue today – an upcoming article will discuss the results that we obtained – because I would like to discuss how this new activity has impacted our way of coding and changed how I review the code that is written.
One morning, I was faced with this excerpt:

The first thing that came to my mind was, “why on earth would you initialise variables if you are just going to exit the function right away, without having used them?”.
I realised that in just a few months of immersing myself in eco-coding manifestos and various articles (not just about coding, either) and asking myself questions, I had developed a habit of hunting down the unnecessary.
A few days later, there was lots of buzz around ChatGPT in Davidson’s Discord forums, and we were starting to experiment a bit.
Rémy had the excellent idea of testing the bot with a problem from the Euler database and changing it to ask for a program written in Rust.
And I must say that it is hard not to be amazed by its answer:

Depending on how the questions guide it – by adding optimised, efficient and the like – the answers vary a bit, but the logic of nested loops is always there.
So, after a quick copy/paste and a few adjustments to the syntax, it compiles, it executes, and we get the right answer. All in less time than it took for me to figure out what the problem was saying. Wow!
A first critical look
On my workstation, it executes almost instantly. If this were 2021, I might have left it there. But “hunting down the unnecessary” is often synonymous with optimisation and triggers my new, loop-related reflexes. Especially since there are two of them nested here!
Ultimately, I think we might be able to get something out of this, and my gut says that it won’t be trivial.
To give you all the facts, I edited the code to count the number of iterations needed to produce the result:
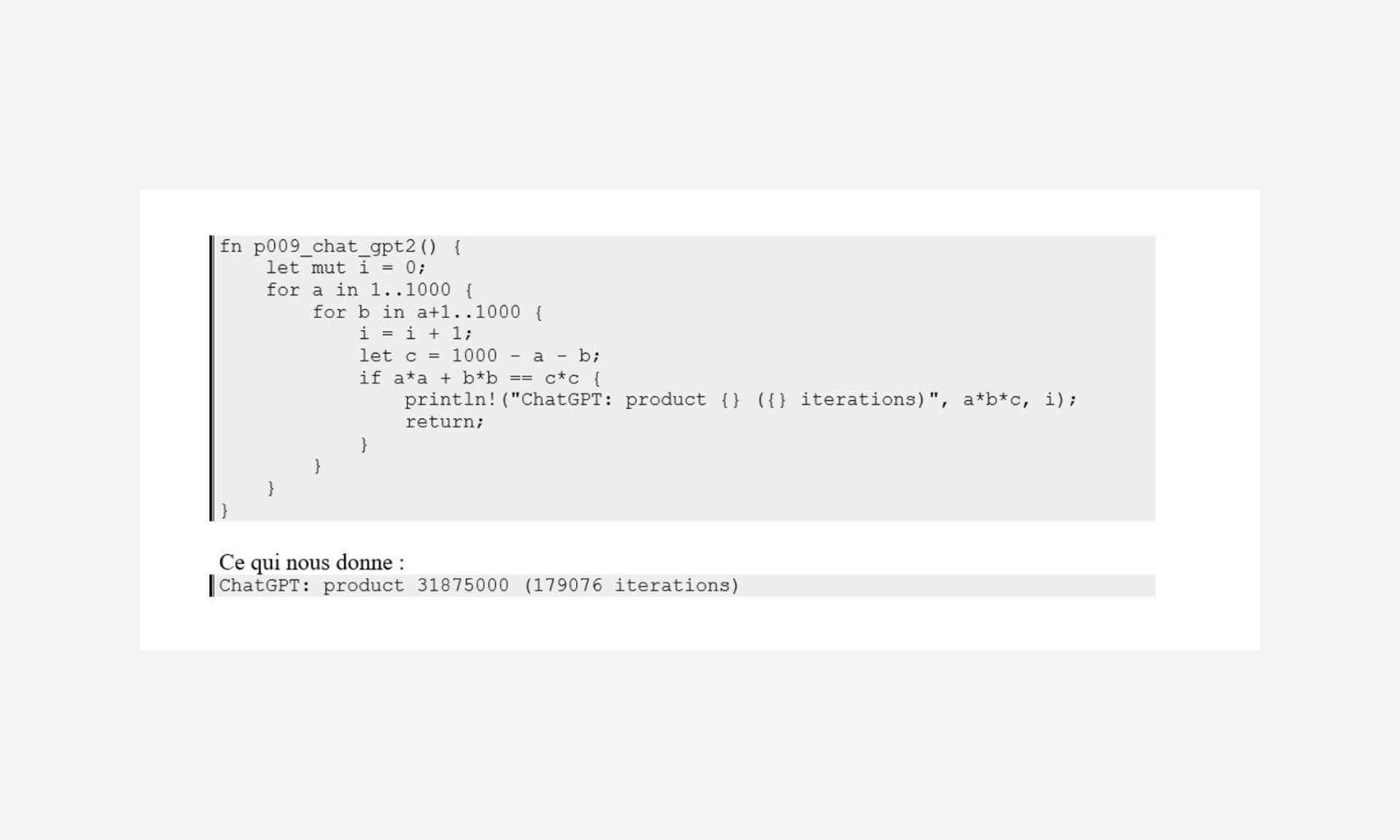
Great! That gives us something to start with.
If we look closer at the program, we can see two classic pitfalls of loops rather easily:
- We test with a list of irrelevant values,
- We exceed limits and get “silly” results with negative c values.
In short, we are using a “brute force” approach – optimised a bit with the second loop starting at a+1 – but which is only acceptable due to the speed of the machine and searching over a small size of 1000.
Here’s a bit of debugging to demonstrate the nonsense of certain tests:

So, we can already make improvements by adjusting the search bounds, but I will leave that for later since we can always restrict searches to relevant values. By that, I mean valid Pythagorean triples.
Reducing the search area
One of the greatest optimisations possible for loops is to reduce the number of test cases. Obviously, if we test a potential of 10,000 cases, we will be less exact than if we tested a potential of 100 cases.
Using a more “standard” programming case, we can obtain significant gains if a database offers a distinguishing criterion that we can use to restrict the dataset, create an index and filter on this criterion.
But filtering is itself an operation that has a cost and, in our case, it is beneficial to look at the nature of what we are dealing with and see if there aren’t any special properties.
A quick web search later and I found Euclid’s formula:

Not bad, since this will restrict the search scope by looping over parameters m and n on valid triples.
Here is an initial attempt at optimisation:

Escaping loops
First, the loops’ bounds are set to be broad and, as noted in the ChatGPT version, we should be able to reduce the number of cases by defining them correctly.
But more accessibly, it is easy to say that if the sum of a, b and c increases upon each iteration, then once 1000 is exceeded, it is possible to escape the loop by varying m and start over with a new value n.
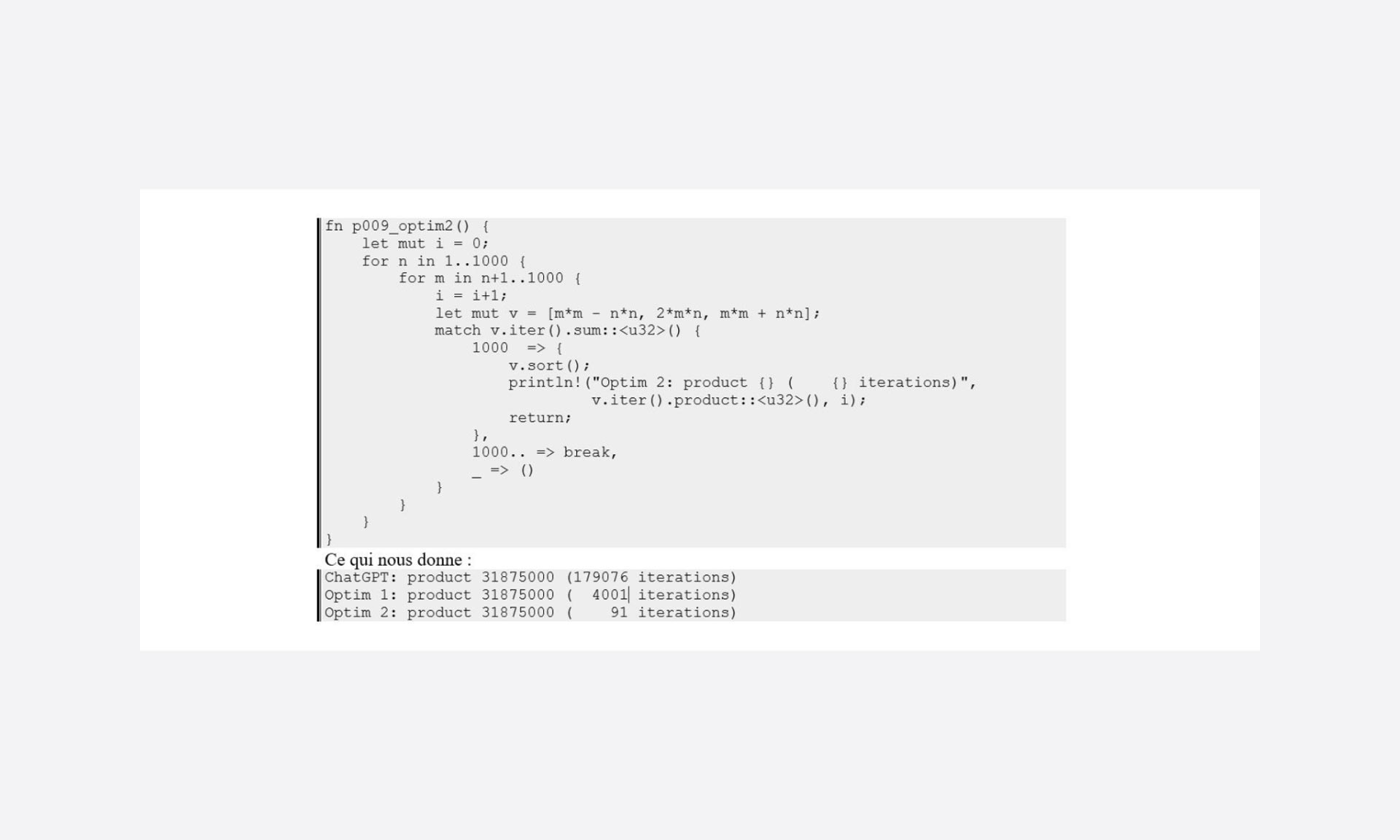
Yes again!
Another great optimisation, but one that only works if you are faced with incremental test sequences.
But on the loop exit conditions alone, the gain is more than significant.
Efficiency of the search method
Despite the drastic reduction in the number of cases to be tested in order to reach the solution, our program continues to test all the possible cases incrementally.
In fact, working on something that is ordered allows us to consider different search algorithms. Given the data range (1000), we could try a binary search approach.
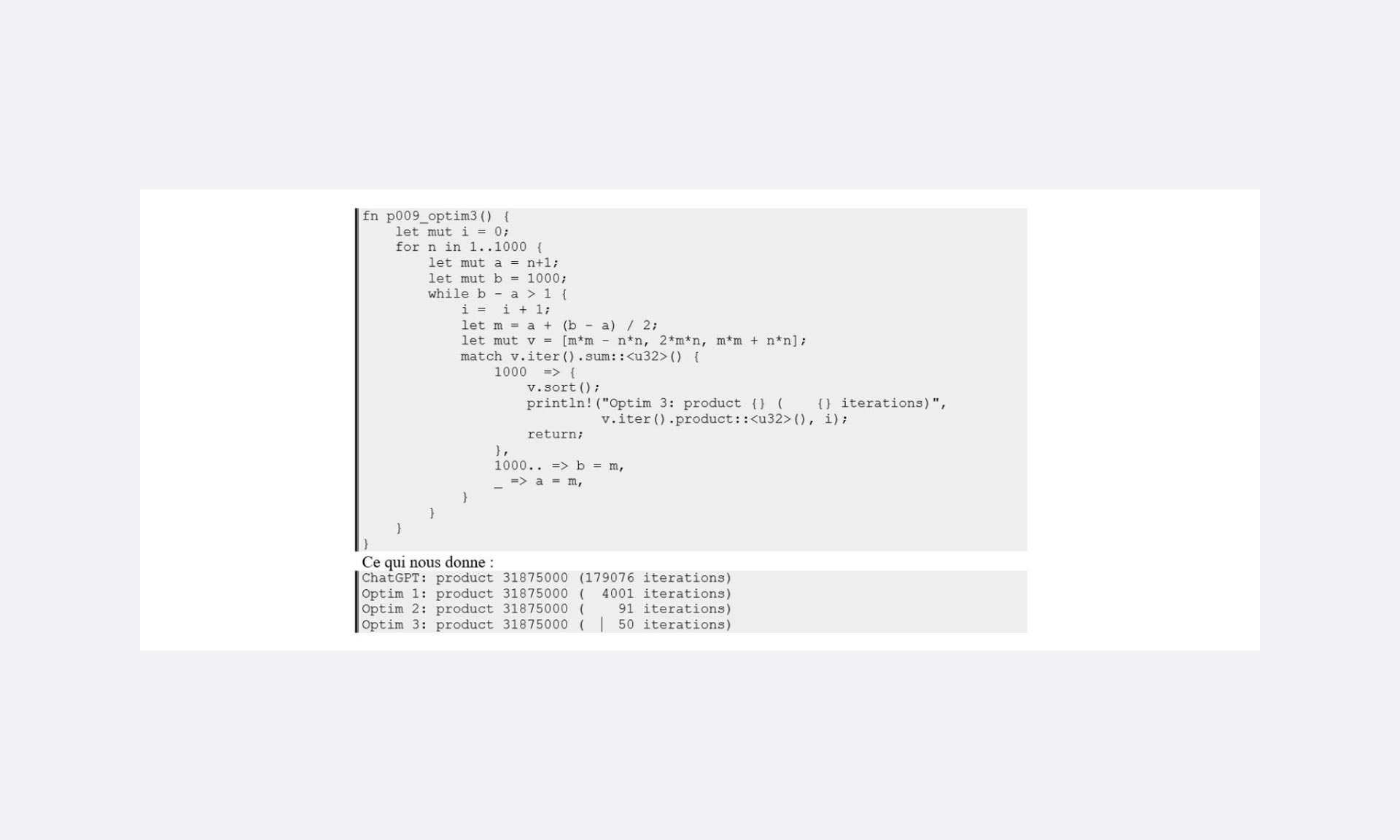
Yes once again!
cancelled out by using this type of search – that doesn’t mean that there is no benefit to it, just that it does not apply to this search method).
The Internet is filled with articles on the benefits and complexity of search algorithms, and many libraries offer them as standard.
What we should remember here is that for lists and ordered loops, depending on the range of data, a quick sort can save many iterations.
Refining the bounds
To reduce the number of tested cases even further, the range of variation of n and m, set at 1000 arbitrarily, should be able to be better adjusted.
Here we are working on a problem with a sum of the triple set to 1000. Given that we are working on increasing iterations, we can pre-calculate the bounds.
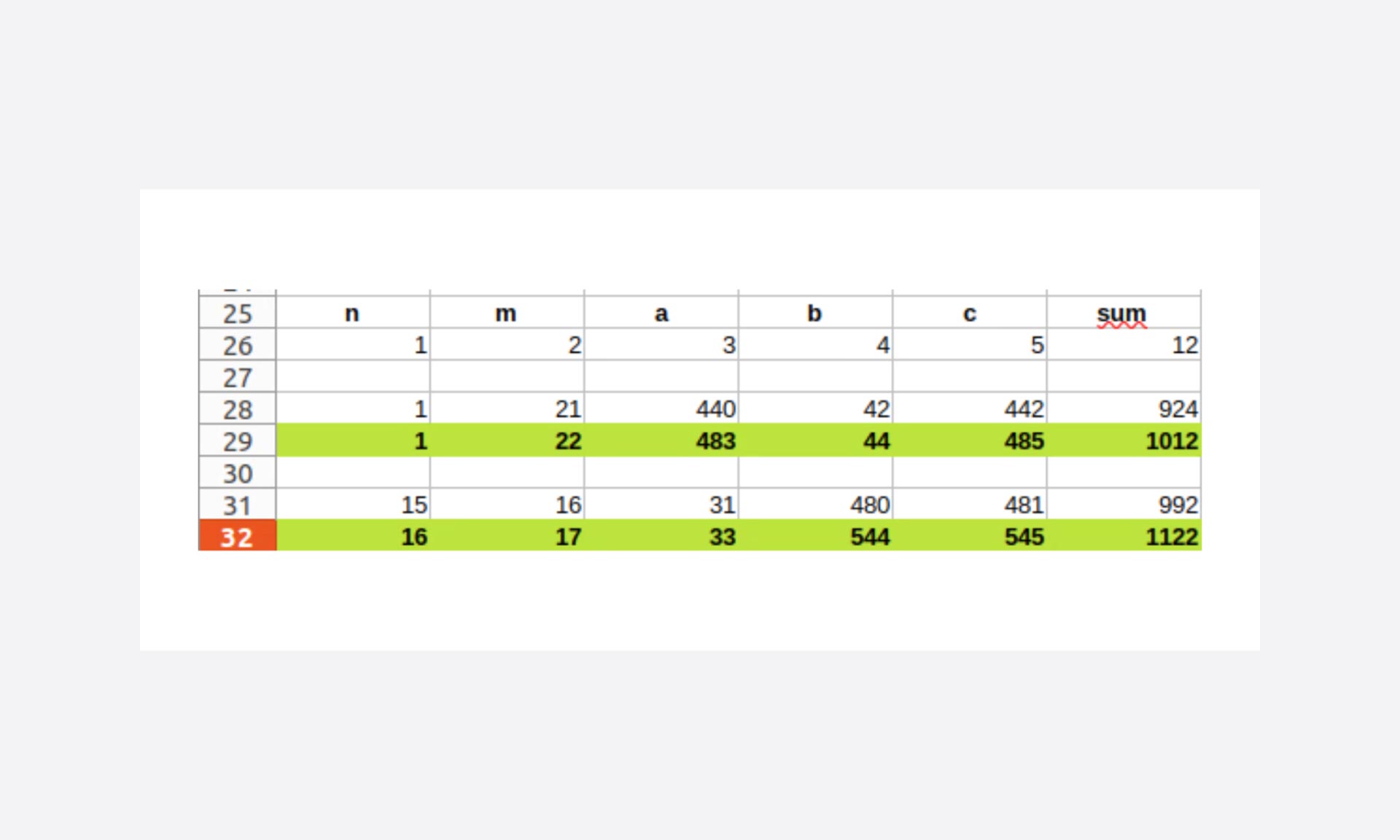
- Where n = 1, m can be no greater than 22
- The limit to find the solution is n = 16 and m = 17
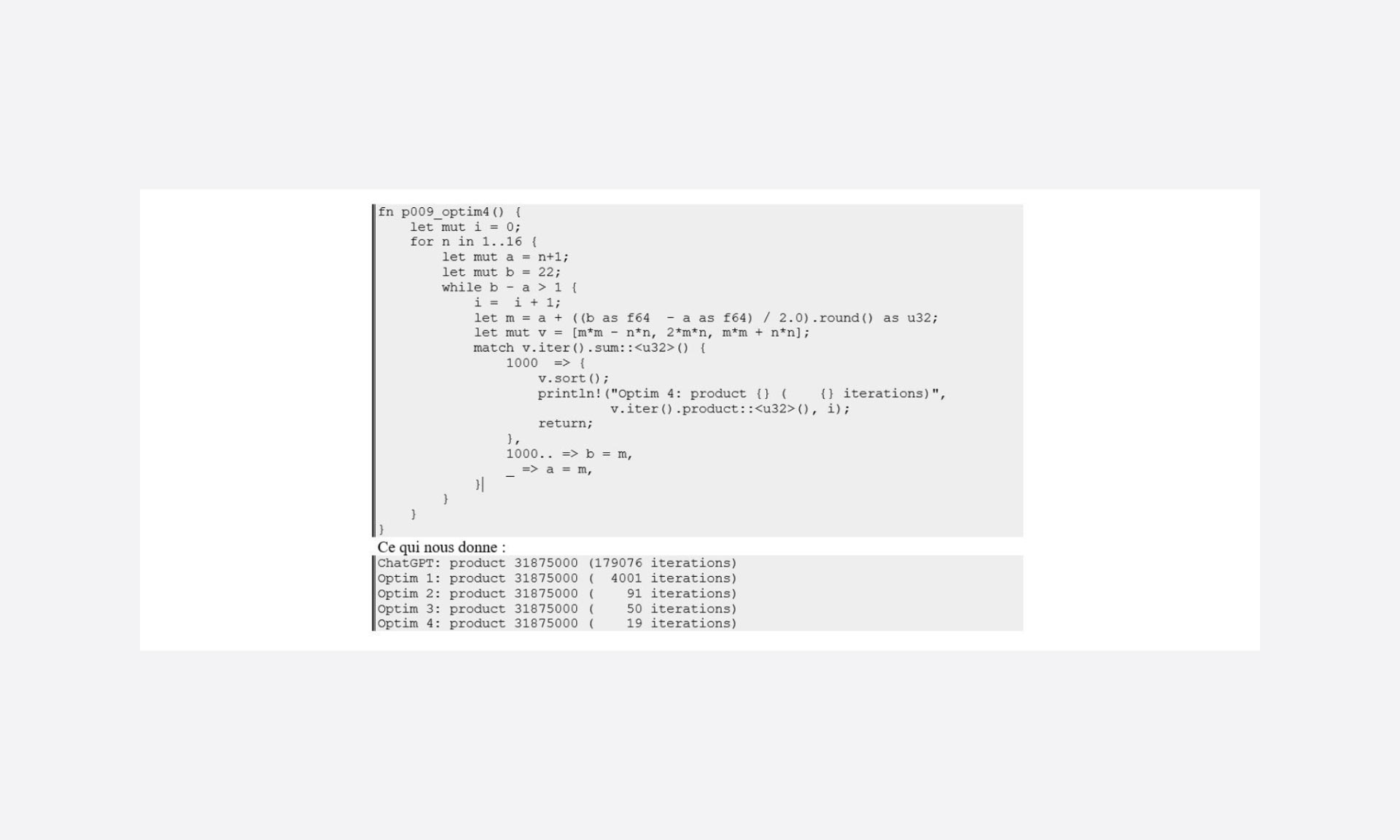
Yes yet again!
Setting the right bounds for loops also helps to avoid many iterations.
Hunting down the unnecessary
Here I have tried to present how a morning of training goes. The process is not optimal, and I am not pretended that the result is either – I am no doubt not well-versed enough in maths for that.
The example chosen here ultimately has little interest given that we are always trying to obtain the same result, and the power of our machines makes this optimisation invisible in terms of user experience (waiting time for the response).
It would not be the same if we wanted to use it for other searches: the sum of a variable of triples (currently 1000).
As developers, we can still see the importance of:
- Minimising data sets
- Adjusting search bounds
- Using sort/search methods
- Exiting loops in nested loops
This means paying attention:
- when creating code yourself
- as a team when reviewing code
This little exercise only presented a small facet of “right tech” thinking applied to software and, even then, I just optimised an algorithm.
The interesting part lies in looking for optimisations without it being triggered by a observed performance problem.
That is the paradigm shift that is underway, looking to anticipate the fewer resources in the future by making better use of them to lead to more sharing, more wealth.
Coding and computing are overly misleading on these issues, since we are in a field where, as long as the user experience does not seem to be impacted, we don’t try to be efficient in how we use the power available to us. We really aren’t very far from the mechanisms that try to delay awareness of environmental issues.
The shameful corollary to this can be summed up in two points:
- We need to overhaul how we look at code to identify what is superfluous – for this, we can use tools like Ecocode.
- Our “managers” and “customers” must also give us the time to do this work, for example using indicators alongside the traditional ones for quality, costs and time.
The software part undoubtedly has the least impact on the carbon footprint, but paying attention and hunting down the unnecessary when designing and writing code has a direct impact on hardware obsolescence by making sure we use it more efficiently.
For those who are curious, I ran a test by searching for the triple with a sum of 50,000.
| Searching for the sum of the triple 5000 | |||
| Iterations | Seconds | Joules | |
| ChatGPT | 449953751 | 9,37 | 113,059315 |
| Optim 4 | 512 | 0,11 | 0,419751 |
Seconds were measured by unix time, and Joules via the vjoules tools from powerapi
I’ll let you work out the order of magnitude, keeping in mind that time is energy consumption in computing.
What if we trained ChatGPT to take into account eco-design problems when producing code?
Vincent CAGNARD - Right Tech developer at Davidson